
robots.txtとは?初心者でもわかる設定方法と注意点を完全解説


「robots.txtって何?」
「検索エンジンからアクセスされたくないページがあるけど、どうしたらいい?」
実は、robots.txtはサイトの重要なページを効率的に検索エンジンに見つけてもらうための便利なファイルです。
適切に設定することで、サーバーの負荷を軽減し、SEO効果を向上させることができます。
本記事では、robots.txtの基本的な概念から具体的な設定方法、よくある失敗例まで、初心者にもわかりやすく解説します。
正しいrobots.txtの設定により、効率的なサイト運営を実現できるでしょう。
1.robots.txtとは

robots.txtとは、検索エンジンのクローラー(自動巡回プログラム)に対して「このページは見に来てよい/ダメ」という指示を出すためのファイルです。
詳しく概要を説明します。
- robots.txtの概要
- robots.txtが必要なケース
なお、検索エンジンの仕組みやクローラーの役割については、以下の記事で詳しく解説しています。


(1)robots.txtの概要
robots.txtは、検索エンジンのクローラーに対してクロール(サイト巡回)の許可や禁止を指示するテキストファイルです。
robots.txtファイルをドメイン直下(例:https://example.com/robots.txt)に設置することで、クローラーがサイトを訪問した際に最初にこのファイルを読み込みます。
ただし、重要なポイントとして、robots.txtはクロール制御のためのファイルであり、検索結果からページを完全に除外する機能ではありません。
検索結果に表示させたくない場合は、metaタグの「noindex」という別の方法を使用する必要があります。
noindexタグの概要や設定方法の詳細については、以下の記事もご参照ください。

(2)robots.txtが必要なケース
robots.txtファイルの設置が特に有効なのは、管理画面や内部ディレクトリのブロックをしたいときです。
WordPressの管理画面(/wp-admin/)など、一般ユーザーに見せる必要のない内部ページを検索エンジンから隠したい場合に活用できます。
また、PDFファイルや大きな画像ファイルなど、クローラーがアクセスするとサーバーに負荷をかけてしまう可能性があるファイルの制御に使用できます。
さらにECサイトなどで、商品の並び替えやフィルタ機能により生成される大量の類似ページを制御し、重要なページに検索エンジンの注意を向けさせることが可能です。
2.robots.txtの役割とSEOへの影響

robots.txtを正しく設定することで、サイトのSEO効果を向上させることができます。
その仕組みと具体的な効果について詳しく見ていきましょう。
- クローラーの動作を制御できる
- サーバー負荷やクロール効率を最適化する
- インデックスの除外効果はない
(1)クローラーの動作を制御できる
robots.txtを使用することで、様々な検索エンジンのクローラーに対して個別に指示を出すことができます。
例えば、Googleのクローラー(Googlebot)には特定のフォルダへのアクセスを許可し、他の検索エンジンには制限をかけるといった細かい制御が可能です。
また、すべてのクローラーに対して一律の指示を出すこともできるため、サイトの運営方針に応じて柔軟に設定することができます。
ただし、robots.txtはあくまで「お願い」のような性質をもち、すべてのクローラーが必ず指示に従うとは限りません。
一般的な検索エンジン(Google、Bing、Yahoo!など)のクローラーは指示に従いますが、悪意のあるボットなどは無視する可能性があります。
(2)サーバー負荷やクロール効率を最適化する
適切なrobots.txt設定により、サーバーの負荷軽減とクロール効率の向上を実現できます。
不要なページへクローラーがアクセスしないようにすることで、サーバーのリソースを節約できます。
特に大容量のファイルや動的に生成されるページがある場合に効果的です。
さらに、クロールの時間と労力を重要なページに集中させることができるので、新しいコンテンツのインデックス登録の速度が速くなる効果も期待できます。
インデックス登録の意義やSEO上の効果については、以下の記事も合わせてご覧ください。

(3)インデックスの除外効果はない
robots.txtではインデックス除外の効果はありません。
robots.txtはクロール(巡回)の制御をするものであり、インデックス登録の制御を制限するものではないためです。
そのため、外部サイトからリンクされているページは、robots.txtでクロールを禁止していても、検索結果に表示される可能性があります。
検索結果に表示させたくないページには、metaタグで「noindex」を設定しましょう。
3.robots.txtの基本構造

robots.txtファイルは、シンプルなテキスト形式で記述されており、ルールに従った記述が必要です。
まずは構成要素から理解しましょう。
| 要素名 | 説明 |
|---|---|
| User-agent(対象クローラー名) | どのクローラーに対してルールを適用するかを指定します。 |
| Disallow(クロールを許可しないパス) | 指定したディレクトリやファイルへのクローラーアクセスを禁止します。 |
| Allow(クロールを許可するパス) | 基本的に禁止している中で、例外的にアクセスを許可するパスを指定します。 |
| Sitemap(サイトマップの場所) | XML サイトマップファイルの場所を検索エンジンに知らせます。 |
| #(コメント行) | ファイル内にメモや説明を記述する際に使用します。 |
これらの要素を組み合わせることで、サイトに最適なクローラー制御を実現できます。
また、空白行や改行記述する順序にも注意が必要で、正しい文法で記述しないと意図した通りに動作しない可能性があります。
4.robots.txtの正しい構文と書き方ルール

robots.txtファイルを正しく動作させるために、守るべき構文ルールがいくつかあります。
具体的には、以下のような点を押さえておきましょう。
- DisallowとAllowの構文ルール
- User-agentの複数指定ルール
- ワイルドカード(*)や$の使い方
- Sitemapの位置・書き方
- Googleが推奨する構文ルール
細かなルールを理解して、エラーのない設定を行うことが重要です。
(1)DisallowとAllowの構文ルール
robots.txtにはDisallow(許可しない)とAllow(許可する)を指定します。
DisallowとAllowではAllowの方が優先されるので、優先順位を理解したうえでrobots.txtを記述しましょう。
User-agent: *
Disallow: /admin/
Allow: /admin/public.html
つまり、上記の例では「/admin/」フォルダ全体は禁止ですが、「/admin/public.html」ファイルだけは例外的にアクセスを許可するという意味になります。
まずルールとして先頭にスペースを入れると作動しないので、余計なスペースがないかチェックをしましょう。
また、Disallow/Allowの後に続く:(コロン)の後には、必ず半角スペースを入れる必要があります。
(2)User-agentの複数指定ルール
複数の検索エンジンに対して異なるルールを適用したい場合は、ブロック単位で明確に分ける必要があります。
User-agent: Googlebot
Disallow: /test/
User-agent: Bingbot
Disallow: /staging/
User-agent: *
Disallow: /private/
それぞれのUser-agentに対するルールは、空白行で区切ってブロックを分けることが推奨されています。
User-agent: Googlebot
User-agent: Bingbot
Disallow: /test/
このような記述では、どちらのクローラーにルールが適用されるか曖昧になるため、正しい例のようにブロックを分けて書くようにしましょう。
(3)ワイルドカード(*)や$の使い方
Googleは正規表現的記法の一部に対応しており、より柔軟な設定が可能です。
正規表現的記法(正規表現記法)は、文字列のパターンを表現するための特殊な記号システムです。
*(ワイルドカード)や$の使用により、この文字に対応する文字列を入力せずに、効率的にデータを処理できます。
たとえば、以下のように記述することができます。
User-agent: *
Disallow: /*.pdf$
このコードは「すべてのエージェントに対して、末尾が「.pdf」で終わるすべてのファイルへのアクセスを禁止する」という意味になります。
(4)Sitemapの位置・書き方
XML サイトマップの場所をrobots.txtで指定すれば、検索エンジンに効率的なクロールを促すことができます。
User-agent: *
Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
Sitemapの記述は、一般的にファイルの末尾に配置し、必ず完全なURL(https://から始まる絶対URL)で記述するようにしましょう。
なお、複数のサイトマップがある場合は、それぞれ別の行で記述できます。
サイトマップの概要や意義、作成方法については以下の記事も参考になります。



(5)Googleが推奨する構文ルール
robots.txtの作成において、Googleが推奨する構文ルールを覚えておきましょう。
これにより確実にクローラーに指示を伝えることができます。
- 1行につき1つの指示を記述する
- 大文字と小文字を正確に区別する
- 不要な空白や特殊文字を入れない
- UTF-8エンコーディングで保存する
これらのルールを守ることで、意図した通りにクローラーを制御できるでしょう。
5.robots.txtの設置方法
![]()
robots.txtファイルを正しい場所に設置することで、検索エンジンに適切に認識させることができます。
設置場所と具体的な手順を確認しておきましょう。
- robots.txtの設置場所はドメイン直下にする
- アップロードの手順
(1)robots.txtの設置場所はドメイン直下にする
robots.txtファイルは必ずドメインの直下(ルートディレクトリ)に設置する必要があります。
ドメイン直下以外の場所に設置したとしても、検索エンジンは読み込むことができません。
○https://example.com/robots.txt
○https://www.example.com/robots.txt
×https://example.com/seo/robots.txt
×https://example.com/wp-content/robots.txt
なおWordPressを使用している場合でも、wp-contentフォルダの中ではなく、その上位のルートディレクトリに設置するようにしてください。
(2)アップロードの手順
robots.txtファイルのアップロード方法は、使用しているサーバーによって異なります。
例として、メジャーなサーバーであるエックスサーバーでの設置手順を紹介します。
エックスサーバーでは、ファイルマネージャーを使用して簡単にアップロードできます。
まずはエックスサーバーの「サーバーパネル」にログインし、上部メニューから「ファイルマネージャ」を開いてください。
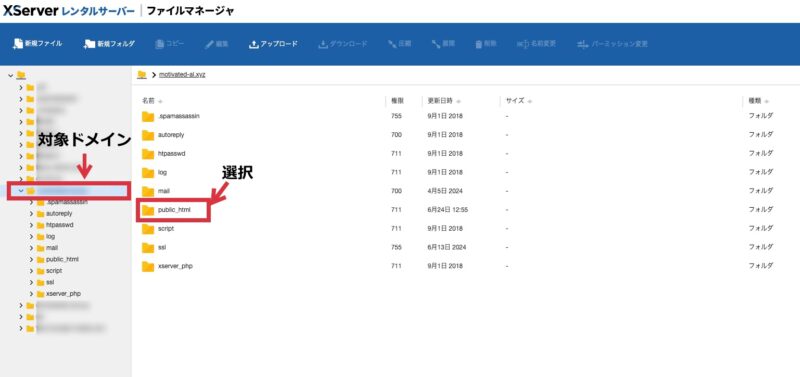
次に対象ドメインの「public_html」フォルダを開きます。
上記のファイルを選んだ後は、上部メニューでアップロードまたは新規作成を選び、ファイルをアップロードまたはrobots.txtファイルを作成すれば完了です。
6.robots.txtの設定パターン別の実例集

実際のWebサイト運営でよく使用される、robots.txtの設定パターンを具体例とともに紹介します。
- 全クローラーに特定ディレクトリを拒否する例
- Googlebotだけに制限をかける例
- 部分許可+制限の併用例
- 複数のUser-agentを使い分ける例
- WordPressサイトでの実装例
順に見ていきましょう。
(1)全クローラーに特定ディレクトリを拒否する例
すべてのクローラーに対して特定ディレクトリを拒否する場合は、以下のように記述しましょう。
User-agent: *
Disallow: /admin/
この構文の意味は以下のようになります。
| 記述内容 | 効果 |
|---|---|
| User-agent: * | すべての検索エンジンボット(Google、Bing、Yahoo!など)に適用 |
| Disallow: /admin/ | /admin/フォルダ内のすべてのコンテンツをクロール禁止 |
WordPressやCMSの管理画面(/admin/や/wp-admin/)など、一般ユーザーに見せる必要のない内部ページを隠したい場合に活用できます。
(2)Googlebotだけに制限をかける例
Googlebotなど特定の検索エンジンにのみ制限をかけたい場合は、以下のように設定しましょう。
User-agent: Googlebot
Disallow: /private/
この構文の意味は以下のようになります。
| 記述内容 | 効果 |
|---|---|
| User-agent: Googlebot | この設定はGooglebotにのみ適用される |
| Disallow: /private/ | /private/フォルダ内のすべてのコンテンツをクロール禁止 |
例えば、Googleの検索結果には表示させたくないものの、他の検索エンジン(BingやYahoo!など)では表示を許可したい場合に使用します。
具体的には、地域限定のコンテンツやテスト用ページなどで活用すると良いでしょう。
(3)部分許可+制限の併用例
基本的にクローラーのアクセスを禁止するものの、部分的に許可したい場合には以下のように記述します。
User-agent: *
Disallow: /img/
Allow: /img/logo.png
この構文の内容は以下のとおりです。
| 記述内容 | 説明 |
|---|---|
| User-agent: * | すべての検索エンジンボットに適用 |
| Disallow: /img/ | /img/フォルダ内のすべてのファイルへのアクセスを禁止 |
| Allow: /img/logo.png | 禁止されたフォルダの中で、このファイルだけはクロールを許可 |
商品画像などを大量にブロックしたいが、ロゴ画像や代表的な画像だけは検索エンジンに認識してもらいたい場合などに有効な方法です。
(4)複数のUser-agentを使い分ける例
複数の検索エンジンに対して、それぞれ異なるルールを設定したい場合の記述例を紹介します。
User-agent: Googlebot
Disallow: /test/
User-agent: Bingbot
Disallow: /staging/
User-agent: *
Disallow: /private/
この構文の意味は以下のようになります。
| 対象クローラー | 記述内容 | 説明 |
|---|---|---|
| Googlebot | User-agent: Googlebot<br>Disallow: /test/ | /test/ フォルダをブロック |
| Bingbot | User-agent: Bingbot<br>Disallow: /staging/ | /staging/ フォルダをブロック |
| その他すべて | User-agent: *<br>Disallow: /private/ | /private/ フォルダをブロック |
検索エンジンごとに見せたいコンテンツが異なる場合や、段階的なテスト運用を行いたい場合に活用しましょう。
(5)WordPressサイトでの実装例
WordPressサイトでよく使用される記述例を紹介します。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /?s=
Sitemap: https://example.com/sitemap.xml
この構文の意味は以下のようになります。
| 記述内容 | 説明 |
|---|---|
| User-agent: * | すべてのクローラーに対してルールを適用 |
| Disallow: /wp-admin/ | WordPress管理画面全体をブロック |
| Allow: /wp-admin/admin-ajax.php | 必要なAjax機能のみ例外的に許可 |
| Disallow: /?s= | サイト内検索結果ページ(?s=)をブロック |
| Sitemap: https://example.com/sitemap.xml | サイトマップの場所を指定 |
WordPressサイトで検索結果ページが大量にインデックスされてしまうことを防ぎ、重要なコンテンツページに検索エンジンをクロールさせられます。
7.robots.txtの動作を確認する方法

robots.txtファイルを設置した後は、robots.txtが正しく動作しているかの確認が必要です。
簡単にチェックできる方法をご紹介します。
- robots.txtのURLを直接開いて確認する
- robots.txt Testerを使う
(1)robots.txtのURLを直接開いて確認する
最も簡単な確認方法は、ブラウザで直接robots.txtのURLにアクセスすることです。
ブラウザのアドレスバーに「あなたのサイトURL/robots.txt」を入力して、ファイルの内容が表示されるか確認してみましょう。
正常に動作していれば、設定した内容がそのまま表示されるはずです。
もしも設定が誤っている場合は、以下のようなエラーが表示されます。
- 404エラー:ファイルが正しい場所に設置されていない
- 文字化け:ファイルの文字コードが正しくない
- 内容が表示されない:ファイルの権限設定に問題がある
エラーの内容によってその原因は概ね特定できるので、再度ファイルをアップロードして、正しく動作するか再確認しましょう。
(3)SEOツールのテスターを使う
Google以外にも、オンラインで利用できるテストツールがあります。
お使いのSEOツールに搭載されている場合は、そちらを使用しましょう。
無料でテストしたい場合は「Robots.txt チェックツール」がおすすめです。
調べたいURLを入力してクリックすれば、独自に正しくrobots.txtが設置されているか、エラーがないかをチェックできます。
8.robots.txtでやってはいけないミスと対処法
![]()
robots.txtの設定でよく発生するミスと、その対処法について詳しく解説します。
- noindexとの併用をしない
- AllowとDisallowの優先順位を間違えない
- Sitemap未記述でクロール効率が下がる
- User-agentのスペルミスや空白エラーが起きる
- 全ページを誤ってDisallowしてしまう
- テスト環境のrobots.txtを公開してしまう
これから自社のサイトに設定を行う場合には、注意を払いましょう。
(1)noindexとの併用をしない
robots.txtとnoindexタグを間違った方法で併用すると、期待した効果が得られません。
これは、robots.txtでブロックされたページは、クローラーがアクセスできないため、HTMLに記述されたnoindexタグを読み込めないことに理由があります。
結果として、noindexの効果が発揮されず、場合によっては検索結果に表示されてしまう可能性があるのです。
検索結果に表示させたくないページは、robots.txtではなくnoindexタグのみを使用しましょう。
(2)AllowとDisallowの優先順位を間違えない
AllowとDisallowの記述順序や優先順位を誤解すると、意図しない動作になってしまいます。
基本的にrobots.txtでは、より詳細なパス指定をしているものが優先されます。
優先度が同じ場合は、Allowの方が優先される仕様です。
この優先度を間違えてしまうと、意図せずクロールして欲しくないページがクロールされるかもしれません。
優先順位を確認しつつ、正しくrobots.txtを記述しましょう。
(3)Sitemap未記述でクロール効率が下がる
robots.txtにサイトマップの場所を記述していないと、検索エンジンの巡回効率が低下する可能性があります。
サイトマップを指定することで、検索エンジンに重要なページの存在を効率的に伝えることができます。
WordPressサイトの場合、プラグインが自動生成するサイトマップのURLを確認して記述しましょう。
(4)User-agentのスペルミスや空白エラーが起きる
User-agentの記述でよくあるミスとその対処法をご紹介します。
User-agent:* (コロンの後にスペースがない)
User-Agent: * (Agentが大文字)
user-agent: * (user が小文字)
以上のような構文ミスがあると、robots.txtが正しく動作しません。
コロンの後には必ずスペースを1つ入れ、大文字・小文字を正確に記述するなど基本的なルールを間違えないようにしましょう。
(5)全ページを誤ってDisallowしてしまう
最も深刻なミスの1つが、サイト全体を誤ってブロックしてしまうことです。
User-agent: *
Disallow: /
以上の構文ではサイト全体がクロールされないので、検索結果から完全に除外されてしまうリスクがあります。
そのため設置後はGoogle Search Consoleで動作確認を行い、重要なページがブロックされていないことを確認しましょう。
(6)テスト環境のrobots.txtを公開してしまう
開発・テスト環境で使用していた制限の厳しいrobots.txtを、本番環境にそのまま適用してしまうミスもよく起こります。
本番公開前には必ずrobots.txtの内容を確認し、適切な設定に変更することが重要です。
また、開発環境と本番環境で異なるrobots.txtを管理する仕組みを作ることも効果的でしょう。
9.robots.txtについてよくある質問

robots.txtの設定や運用に関してよく寄せられる質問と、その回答をまとめました。
- robots.txtでURL単位の制御はできますか?
- AllowとDisallowを同時に使った場合は、どのように動作しますか?
- 特定の検索エンジンのみ、クロール対象から除外できますか?
(1)robots.txtでURL単位の制御はできますか?
obots.txtでは個別のURLやファイルを指定してクロール制御することが可能です。
User-agent: *
Disallow: /private-page.html
Disallow: /temp-file.pdf
Allow: /public-folder/important.html
ただし、大量の個別URLを管理するのは難しいため、通常はディレクトリ(フォルダ)単位で制御することが多いです。
個別制御が必要なページが多い場合は、それらを特定のフォルダにまとめて、フォルダ単位で制御すると良いでしょう。
(2)AllowとDisallowを同時に使った場合は、どのように動作しますか?
AllowとDisallowを組み合わせれば、細かい制御が可能になります。
なお、この際に以下の優先順位を間違えないようにしましょう。
- より詳細なパス指定が優先される
- 同じ詳細度の場合、Allowが優先される
この優先順位を反映して記述する例をお見せします。
User-agent: *
Disallow: /images/
Allow: /images/logo.png
Allow: /images/banner/
この設定を文章にすると「/images/フォルダ全体は基本的にクロール禁止だが、/images/logo.pngファイルのみはアクセスを許可する。また、/images/banner/フォルダは許可する」という指示になっています。
このように、大枠で禁止しつつ、必要な部分のみ例外的に許可することができます。
(3)特定の検索エンジンのみ、クロール対象から除外できますか?
User-agentを指定することで特定の検索エンジンのみに制限をかけることができます。
主要な検索エンジンのUser-agent名の書き方を覚えておきましょう。
- Google:Googlebot
- Bing:Bingbot
- Yahoo!:Yahoo Slurp(ただし現在はGoogleの技術を使用)
なお、現在Yahoo!検索はGoogleの検索技術を使用しているため、Googlebotの設定がYahoo!にも影響することを理解しておきましょう。
まとめ
robots.txtは、検索エンジンのクローラーに対してサイトの巡回範囲を指示するための重要なファイルです。
適切に設定することで、サーバー負荷の軽減、クロール効率の向上、重要ページへのクローラーの集中など、様々なSEO効果を期待できます。
ただし、robots.txtはクロール制御のためのツールであり、検索結果からの完全除外を目的とする場合はnoindexタグを使用する必要があります。
設定時には構文ルールを守り、テスト環境の設定を本番に持ち込まないよう注意し、Google Search Consoleなどで定期的に動作確認を行うことが重要です。
小規模なサイトでは必ずしも設置が必要ではありませんが、管理画面の保護やクロール効率化を目的として活用することで、より効果的なサイト運営を実現できるでしょう。
しかし、robots.txtの記述や設置はやや複雑な工程であり、戸惑う方も少なくありません。
そのような場合には、TMS Partners株式会社へご相談ください。
TMS Partners株式会社ではホームページの制作や内部SEOの改善などを包括的にサポートできます。
人気記事



新着記事



カテゴリー
-
 コラム
コラム -
 コラム
コラム -
 コラム
コラム